前言
主要对平时所读大模型、NLG相关paper、观点和信息进行汇总,实时更新。
记录
- HuggingGPT: Solving AI Tasks with ChatGPT in Hugging Face http://t.km/qaodgc 核心用ChatGPT解析意图(任务规划)、模型选择、在专家模型执行任务后(任务执行),根据返回结果利用ChatGPT生成响应(响应生成),设计为一超长的Prompt(见下图1),所以缺点是暂时来说成本很高,优点是利用了很多专家模型。 Time: 2023-04-12


Sparks of AGI一作演讲 https://hub.baai.ac.cn/view/25373, 整体和论文内容一致,对比各项任务中GPT-4的智能,核心观点很有趣:即如何定义GPT-4是否有智能,按照不同维度可不同定义:智力包括推理、计划、解决问题、抽象思维、比较复杂的观点以及快速学习和从经验中学习等能力,GPT-4无法计划、缺乏记忆无法实时学习,其他能力可被定义为AGI。 Time: 2023-04-12
AutoGPT https://github.com/torantulino/auto-gpt 基于GPT-4/3.5 的实验性开源应用程序,相当于给GPT大脑一个内存和身体,设定任务后让其自己解决问题,同时可互联网访问、长期和短期内存管理、文件存储和生成摘要等,在其基础上构造垂类X-GPT,想象空间较大,但未看出整体设置的必要性;类似新应用可参照https://zhuanlan.zhihu.com/p/621132445 Time: 2023-04-12
针对多步推理进行小型语言模型的专门化 https://arxiv.org/pdf/2301.12726.pdf https://hub.baai.ac.cn/view/25238 之前介绍中提到的第四步模型专业化,以专门针对目标任务专门化模型能力,即将大模型能力集中在特定的目标任务上,使用较小模型多步推理来靠近大模型的涌现能力。另外文中提出了包括数据格式、起始模型等选择方法。 Time: 2023-04-06
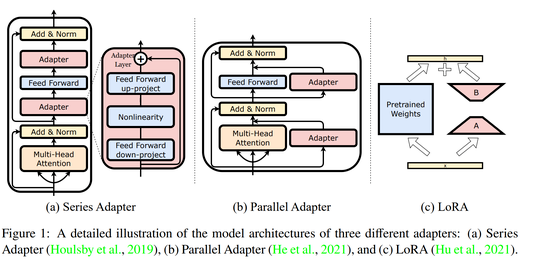
LLM-Adapters https://hub.baai.ac.cn/view/25288 https://arxiv.org/pdf/2304.01933.pdf LLM的局部微调(PEFT)方法,将LLaMa和三种LLM-adapter集成(序列Adapter、平行Adapter和LoRA),在较小规模的LLMs(7B)中使用基于适配器的PEFT,在简单的数学推理数据集的零次推理中,产生了与强大的LLMs(175B)相当的性能。 Time: 2023-04-06
AI 将改变一切 https://hub.baai.ac.cn/view/25313 观点输出文,整篇为翻译文,有些点翻译的较奇怪,提出一系列有趣的观点:

BloombergGPT: A Large Language Model for Finance https://arxiv.org/pdf/2303.17564.pdf 构建和训练了专门用于金融领域的LLM,开发了拥有500亿参数的语言模型——BloombergGPT,核心是利用五项金融任务在Bloom基础上构建模型,参照Chinchilla和现有数据,决定构建50B模型,效果超出Bloom,但未和ChatGPT比较。
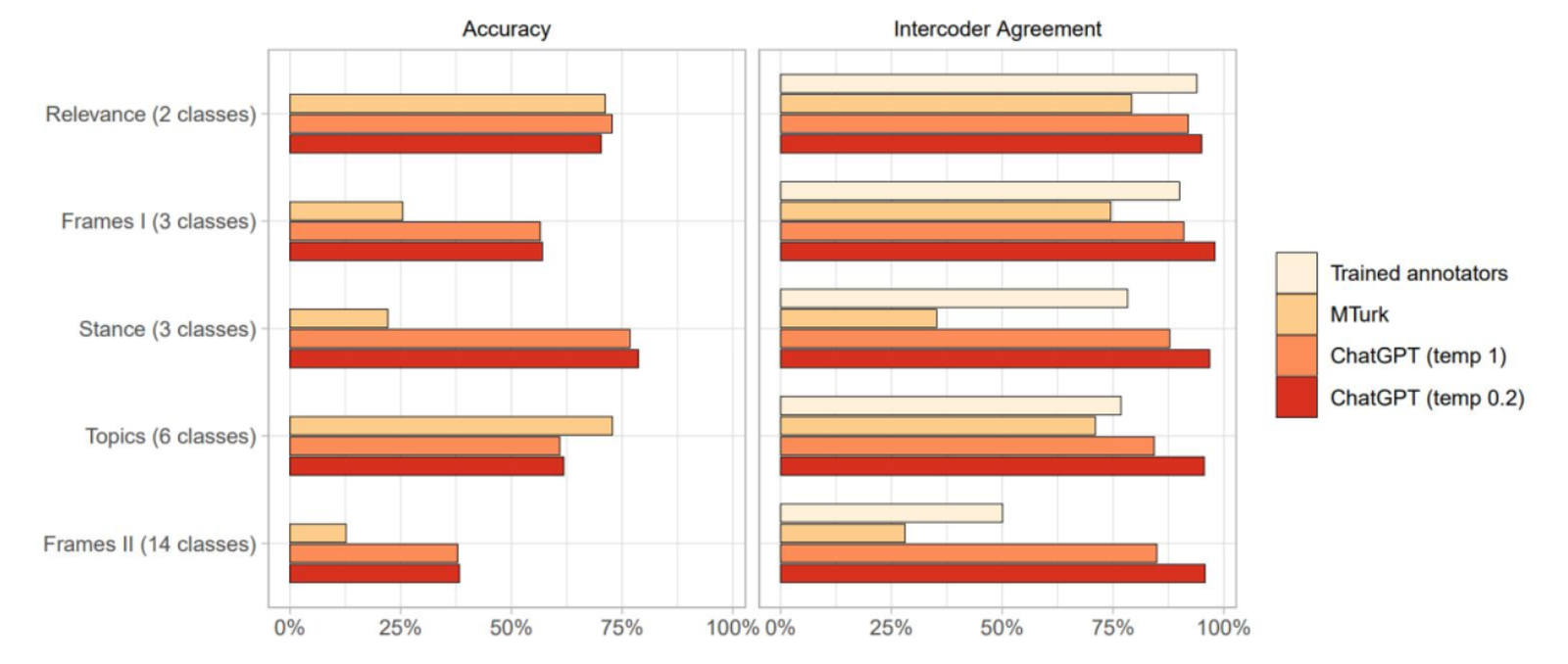
ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks https://hub.baai.ac.cn/view/25112 https://arxiv.org/abs/2303.15056 ChatGPT在包括相关性、立场、主题和两种框架检测任务中的性能超过人工众包工人,在五分之四的任务上,ChatGPT 的零样本准确率高于 MTurk,且成本便宜20倍。
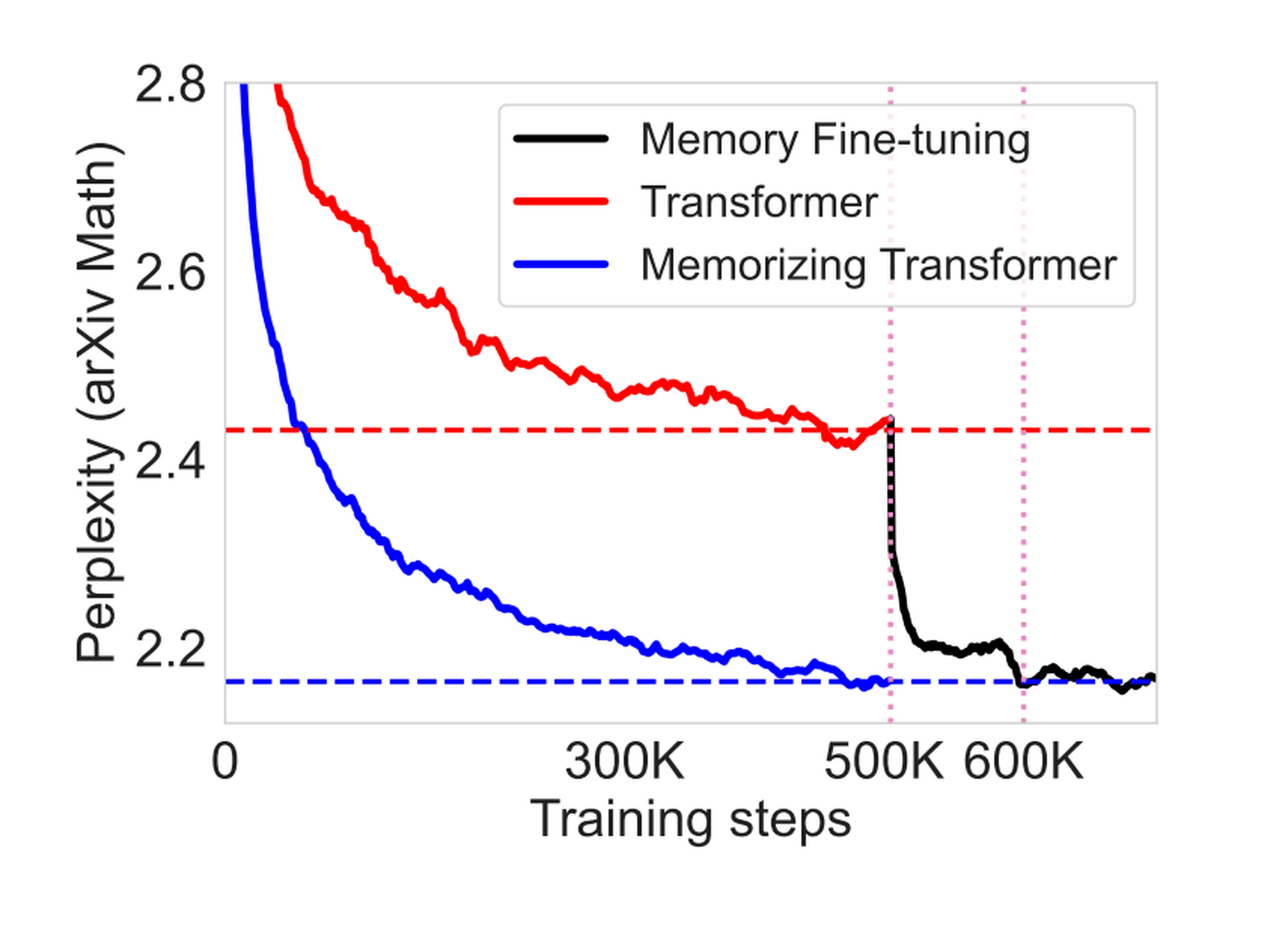
- MEMORIZING TRANSFORMERS https://arxiv.org/pdf/2203.08913.pdf https://hub.baai.ac.cn/view/24957,尝试增加“记忆”机制,提出了kNN-augmented attention,通过使用k-nearest-neighbor lookup外部存储器,增加模型可关注的上下文长度。文中包括从头预训练,或在预训练模型基础上增加记忆,但效率未提及,KNN-LM效率是个问题。
为什么现在的LLM都是Decoder-only的架构? https://mp.weixin.qq.com/s/ZsHX-M9pisUvG9vqfzdzTQ 苏剑林提出:LLM 之所以主要都用 Decoder-only 架构,除了训练效率和工程实现上的优势外,在理论上是因为 Encoder 的双向注意力会存在低秩问题,在同等参数量、同等推理成本下,Decoder-only 架构就是最优选择。没太看懂,需要思考。
Lilian Weng新博文:关于提示工程的介绍 http://t.km/2ssfg0 http://t.km/4r1s5f 关于Prompt Engineering的汇总介绍,包括基础提升工程、指令提示、CoT、自动提示、知识增强(包括外部调用、检索等)等Prompting,详细内容会借鉴并更新在《大型语言模型(LLM)的使用和思考》中。
https://hub.baai.ac.cn/view/24740 ,提出对于涌现能力的分析和观点,1是涌现能力在物理学、进化生物学等自然科学中同样存在,如物理学中水的固化;2是涌现能力可能和评价方式有关,比如只评价目标没有过程指标时,可能会凸显涌现能力,但其实是渐进式发展的;3是讨论模型是否可以做到更大,结论是受数据所限。
用大语言模型GPT-3直接替代传统搜索引擎: https://arxiv.org/abs/2209.10063 , https://mp.weixin.qq.com/s/JDJ0JdW77NyRaWRFH2Jdkw ,核心即先生成再阅读(Generate-then-Read),首先向大型语言模型提示(prompt)生成基于给定问题的上下文文档,然后阅读生成的文档以产生最终答案,和基于检索增强的LM思想一致。

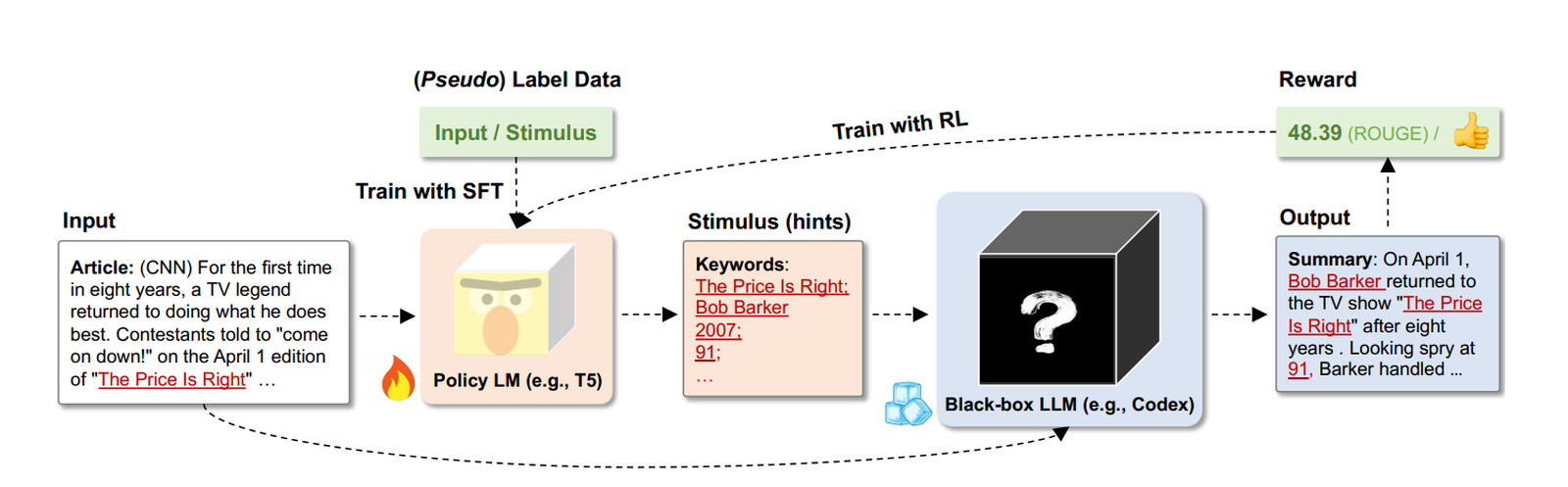
- Guiding Large Language Models via Directional Stimulus Prompting https://arxiv.org/pdf/2302.11520.pdf 使用policy LM生成一个stimulus(一组关键词),即加了一步中间过程:原文-关键词-输出,关键词这里叫stimulus(刺激),剩余方式和ChatGPT一致,SFT->RL。
- The Capacity for Moral Self-Correction in Large Language Models https://arxiv.org/pdf/2302.07459.pdf 用“魔法”对抗“魔法”,核心给大模型增加新的指令(IF),新的思考时间(CoT)来引导大模型减少有害输出,让其自我修正,在实际应用中,也可以增加相关的Prompt,很大概率可以解决,但非根本解决方案。
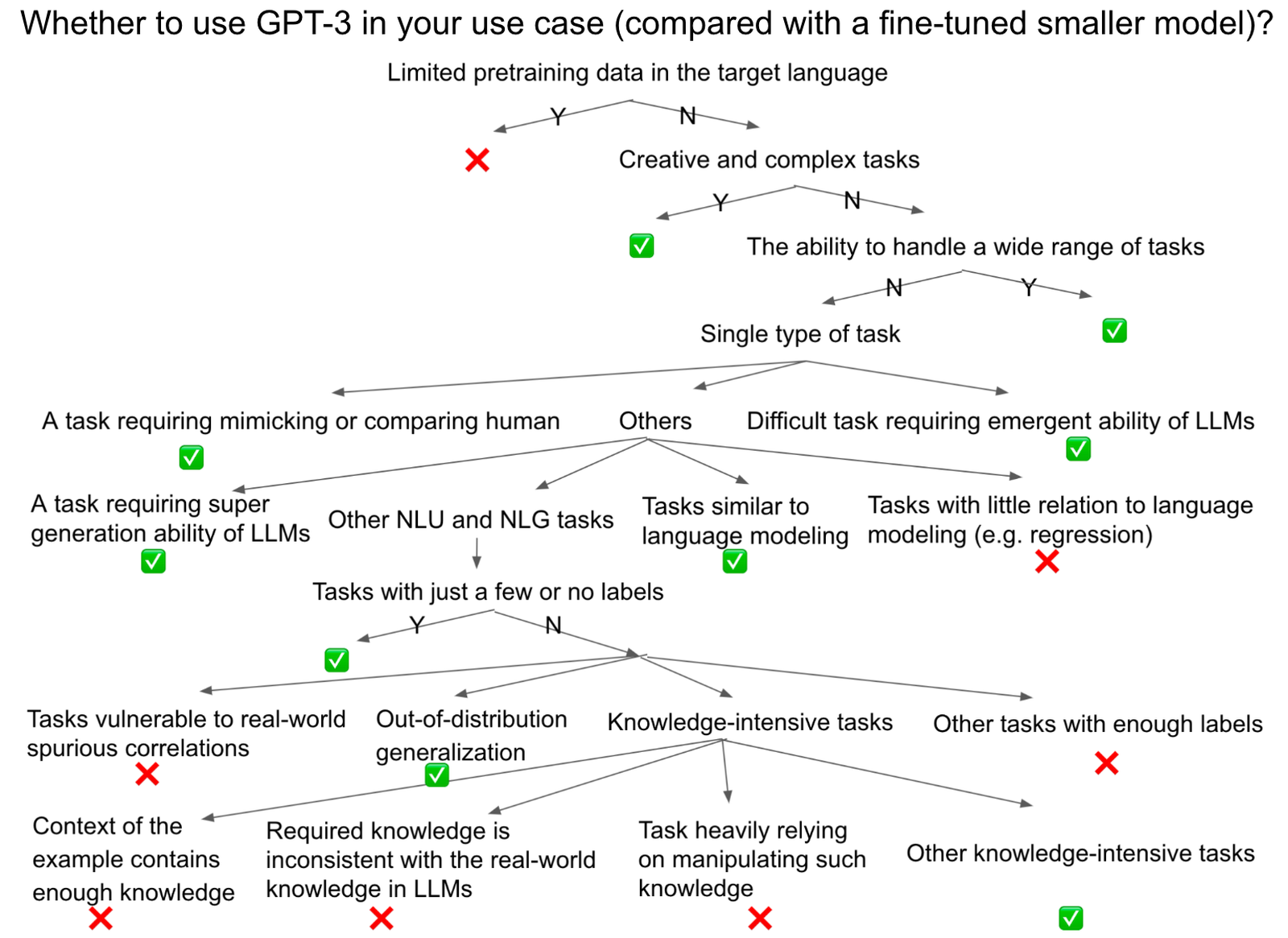
- Why did all of the public reproduction of GPT-3 fail? https://hub.baai.ac.cn/view/24306 https://jingfengyang.github.io/gpt ,写的很好很详尽的一篇文字,解释其他大模型无法复现GPT3的原因,同时给出使用LLM的decision tree,非无脑使用,很多时候在确定任务集,使用微调百亿模型即可达到SOTA。
ChatGPT必读论文、博客和API工具(含中文指南): https://hub.baai.ac.cn/view/24176, 很有用的ChatGPT相关信息汇总。
张栋:ChatGPT 制胜公式: https://hub.baai.ac.cn/view/24166, 张提出,ChatGPT = 50% 数据 + 30% 场景 + 10% 算力 + 10% 团队 ,很有趣的观点。
福布斯:下一代大型语言模型 https://www.forbes.com/sites/robtoews/2023/02/07/the-next-generation-of-large-language-models/?sh=1584307d18db, 文中观点合理,主要针对ChatGPT的缺点,提出LLM的升级更新需:1)可以生成自己的训练数据来提高自己的水平;2)可以自我核实事实的模型,这是ChatGPT目前版本不具有的能力;3)大量稀疏的专家模型,类似MoE的稀疏触发;个人觉得还有专门的存储模块。
ChatGPT失败汇总: https://hub.baai.ac.cn/view/24147, 主要提出1. ChatGPT拥有常识的程度和获得常识的方法不确定;2. ChatGPT在多大程度上记忆与理解他们产生的东西,完全捕捉人类的思想,仍然是未知的;3. ChatGPT有必要进一步改进,提供回答的自信程度。4. 后续研究必须考虑到ChatGPT的道德和社会后果。
数据角度分析,ChatGPT数据集之谜: https://mp.weixin.qq.com/s/9vOc-OyqvzrO_w5LApurbg, 内文主要从二级和三级来源收集和推测各LLM训练数据集大小和来源,提倡确保数据集的详细信息公开透明、所有人都可访问且易于理解是有用、紧迫和必要的。(在我看来ChatGPT应该主要是利用了对话场景的数据,此类大数据主要是训练基础模型时用)
对话大模型中的事实错误:ChatGPT 的缺陷 https://mp.weixin.qq.com/s/CwYb1uLnzrz7s9jXeqSynw, 本文参照综述Survey of hallucination in natural language generation,简述下 NLG 生成“幻觉”文本的成因,接着详细介绍对话任务中的“幻觉”现象,针对对话任务的“幻觉”评估方法和未来研究方向等。
综述|检测大型语言模型生成文本的方法 https://mp.weixin.qq.com/s/FcEscGHEaZpq7deUVZln7g ,本文旨在提供现有大型语言模型生成文本检测技术的概述,并加强对语言生成模型的控制和管理,其中检测方法分为黑盒检测和白盒检测。
https://arxiv.org/abs/2302.04023, 本文提出了一个使用公开数据集定量评估交互式LLM(如ChatGPT)的框架,主要评估了ChatGPT在多任务、多语言和多模态方面 推理、幻觉和交互性的效果,结论是它是一个不可靠的推理器;ChatGPT像其他LLM一样遭受幻觉问题;ChatGPT的交互特性使人能够与底层的LLM协作,以改进其性能。
科技投资人王煜全:OpenAI给科技行业敲响警钟,中国必须要有自主“大模型” https://hub.baai.ac.cn/view/24009 此篇采访有很多深入的思考,包括1)生成式AI为何被巨头关注;2)生成式AI商业模式的讨论;3)ChatGPT技术创新性的意义;4)芯片限制后,我国如何发展自己的AI大模型,值得重复阅读和思考。
https://mp.weixin.qq.com/s/FhtGD8hDxqAUEQDSe-lTTw 此篇为译文,原文观点很敏锐,探讨了谷歌被ChatGPT颠覆的可能性,文中提出谷歌在历史上成功的点是缩短了从问题到答案的距离,并找到了一种将其货币化的方法。而ChatGPT可以利用大量的人类知识来提供一个确切的答案,在提炼、生成、凝聚文本方面具有优势,更具多功能和拓展性。
https://hub.baai.ac.cn/view/23921ChatGPT ChatGPT背后的经济账,原文链接: https://sunyan.substack.com/p/the-economics-of-large-language-models ,文章从训练成本、云计算(推理)成本、各类成本效率轨迹,多方面剖析了将LLM纳入当前产品和新产品的经济可行性,结论是:训练大语言模型并不便宜,但也没那么烧钱,训练大语言模型需要大量的前期投入,但这些投入会逐年获得回报。
New AI classifier for indicating AI-written text https://openai.com/blog/new-ai-classifier-for-indicating-ai-written-text/ 在GPTZero和DetectGPT之后,OpenAI也发布官方AI生成文本分类器,模型细节未释出,主体使用训练数据的人工和机器回应做区分,整体效果暂时只有26% AI-generated 文本被识别正确,最后提及人们比较关注的对教育界的影响和措施。
What Makes a Dialog Agent Useful? https://huggingface.co/blog/dialog-agents 简单介绍了以ChatGPT为首的各ChatBot背后的技术重点,包括人工反馈学习(RLHF)、有监督微调(SFT)、指令学习(IFT)和思维链(CoT)
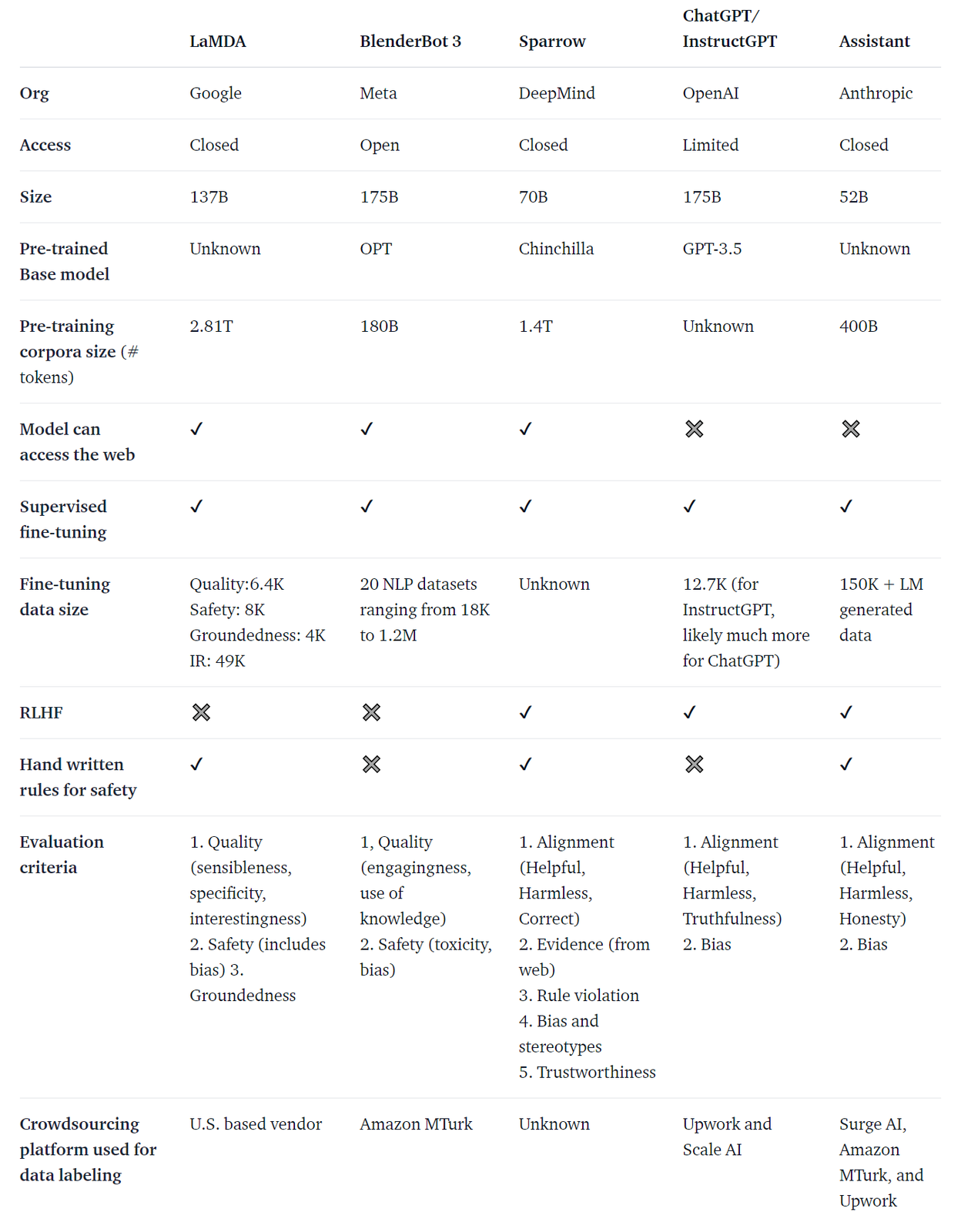
https://hub.baai.ac.cn/view/23717 https://arxiv.org/pdf/2301.07597.pdf 提出了首个「人类-ChatGPT」问答对比语料集,并开发了首套支持双语的ChatGPT检测器,并且进行了广泛的人工测评、语言学分析、检测实验,结论比较有趣,ChatGPT并非“无懈可击”,和人类相比可以看出差距。
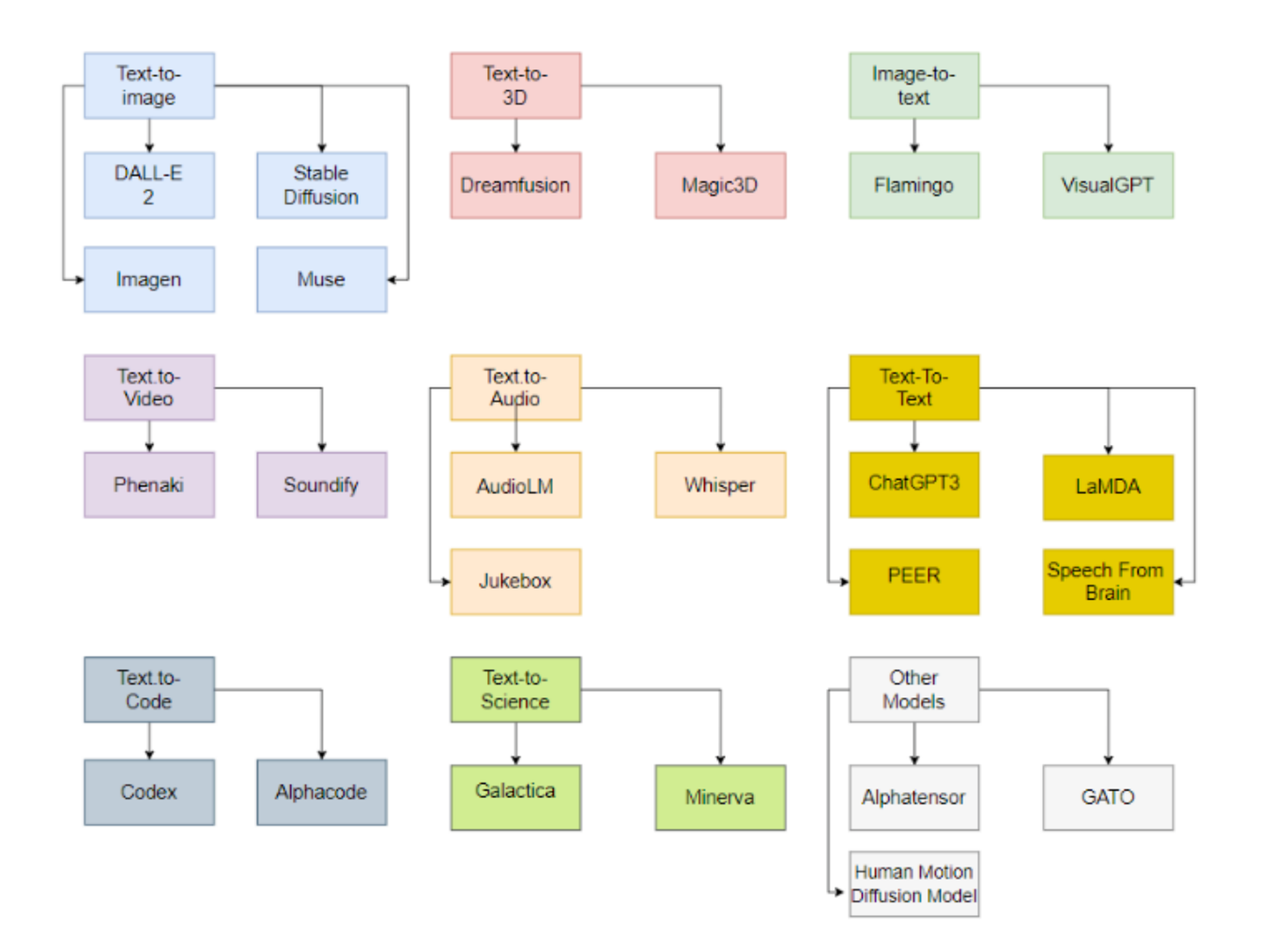
一篇各模态生成模型SOTA的简单综述: https://arxiv.org/pdf/2301.04655.pdf, 方便了解目前各模态的生成sota,图比较粗糙,但归类较好:
有启发的一篇文章:大型语言模型中语言与思想的分离: https://arxiv.org/pdf/2301.06627.pdf"主要提出语言能力应该分为formal competence(形式语言技能)和functional competence(认知能力),前者是目前LLM所胜任的任务,而后者需要针对性建立/开发模块/方法,非next word predition任务所能胜任。
产品角度对于LLMs的看法,相关内文见: https://mp.weixin.qq.com/s/t0Ml7E-CvlKfdaUMBGKJBg 主要观点见下图。
